对人工智能集群的需求激增导致人们对数据中心容量的关注激增,这给电网、发电能力和环境带来了极大的压力。人工智能的建设受到数据中心容量缺乏的严重限制,特别是在训练方面,因为 GPU 通常需要位于同一位置以实现高速芯片到芯片网络。推理的部署受到各个地区的总容量以及即将上市的更好模型的严重限制。
关于瓶颈在哪里有很多讨论——额外的电力需求有多大?GPU 部署在哪里?北美、日本、台湾、新加坡、马来西亚、韩国、中国、印度尼西亚、卡塔尔、沙特阿拉伯和科威特等地区的数据中心建设进展如何?加速器的增长何时会受到物理基础设施的限制?是变压器、发电机、电网容量还是我们跟踪的其他 15 个数据中心组件类别之一?需要多少资本支出?哪些超大规模企业和大公司正在竞相确保足够的容量,哪些将因为没有数据中心容量而措手不及而受到严重限制?未来几年,千兆瓦级和更大的训练集群将建在哪里?天然气、太阳能和风能等发电类型的组合是什么?这是否可持续,或者人工智能的发展会破坏环境吗?
许多人对数据中心建设速度提出了荒谬的假设。甚至埃隆·马斯克也发表了看法,但他的评估并不完全准确。
他表示,上线的人工智能计算似乎每六个月就会增加 10 倍……然后,很容易预测下一个短缺将是降压变压器。你必须为这些东西提供能量。如果公用设施输出 100-300 千伏电压,并且必须一路降压至 6 伏,那么降压幅度就很大。我的不太好笑的笑话是,你需要变压器来运行变压器……那么,下一个短缺将是电力。他们将无法找到足够的电力来运行所有芯片。我想明年,你会发现他们找不到足够的电力来运行所有芯片。
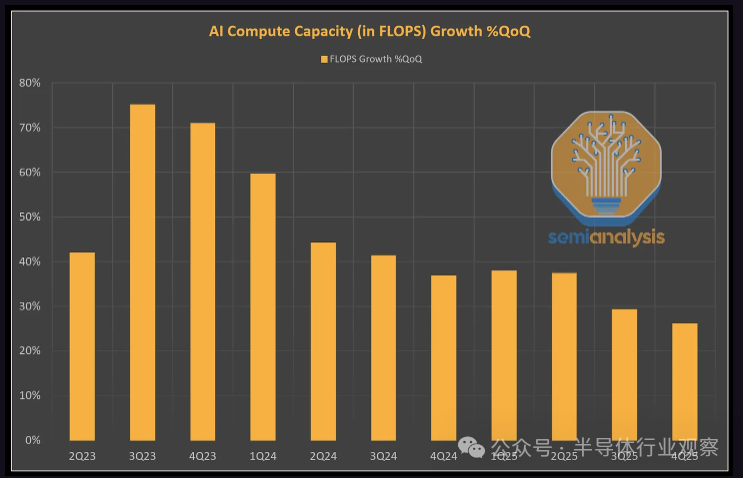
需要明确的是,他对物理基础设施的这些限制的看法基本上是正确的,但计算量并不是每六个月就会增长 10 倍——我们跟踪所有主要超大规模和商业硅公司的 CoWoS、HBM 和服务器供应链,并看到测量的总 AI 计算能力自 2023 年第 1 季度以来,理论峰值 FP8 FLOPS 一直以季度环比 50-60% 的速度快速增长。换而颜值,在六个月内增长远未达到 10 倍,这是因为CoWoS 和 HBM 的增长速度根本不够快。
由transformer驱动的生成式人工智能的繁荣确实需要大量的变压器、发电机和无数其他电气和冷却部件。
许多粗略的猜测或直接危言耸听的叙述都是基于过时的研究。IEA 最近的《电力 2024》报告指出,到 2026 年,人工智能数据中心的电力需求将达到 90 太瓦时 (TWh),相当于约 10 吉瓦 (GW) 的数据中心关键 IT 电力容量,或相当于 730 万台 H100。我们估计,从 2021 年到 2024 年底,仅 Nvidia 就将交付满足 500 万台以上 H100 功率需求的加速器(事实上,主要是 H100 的出货量),并且我们预计到 2025 年初,AI 数据中心容量需求将超过 10 GW。
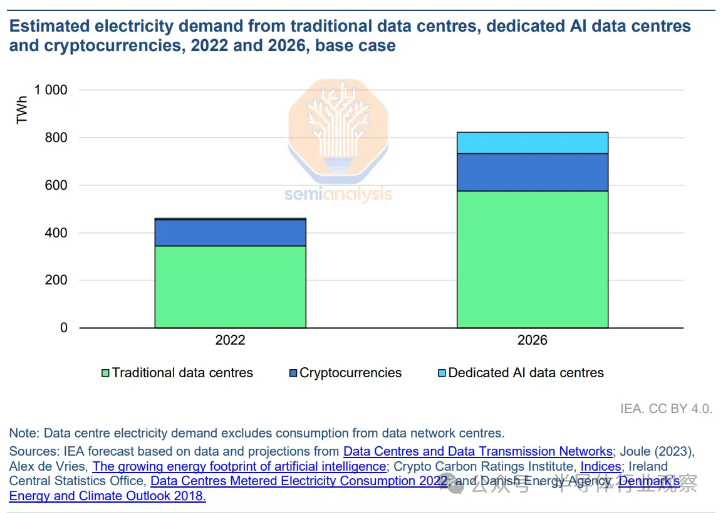
上面的报告低估了数据中心的电力需求,但也有很多高估的地方——一些来自危言耸听阵营的人回收了在加速计算广泛采用之前写的旧论文,这些论文指出了最坏的情况,即数据中心消耗大量电力。到 2030 年,发电量将达到 7,933 TWh,占全球发电量的 24%!
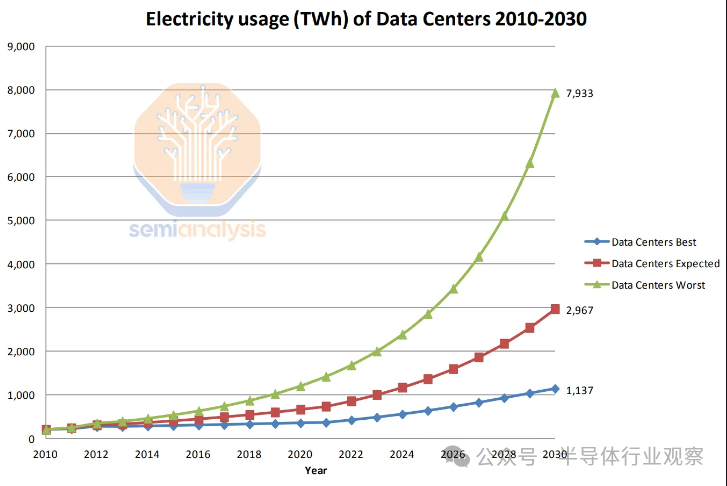
其中许多粗略估计都是基于全球互联网协议流量增长估计的函数,以及因效率增益而抑制的每单位流量使用功率的估计——所有数字都极难估计,而其他数字则采用自上而下的方法在前人工智能时代创建的数据中心功耗估算。麦肯锡的估计也很糟糕,这几乎相当于把手指放在随机的复合年增长率上,然后用精美的图形重复它。
让我们纠正这里的叙述,并用经验数据来量化数据中心的电力紧缩。
我们的方法通过对北美现有托管和超大规模数据中心的 1,100 多个数据中心进行分析来预测人工智能数据中心的需求和供应,包括正在开发的数据中心的建设进度预测,并且首次针对此类类型的研究,我们将其结合起来数据库包含源自, 我们的 AI 加速器模型的 AI 加速器电力需求,用于估计 AI 和非 AI 数据中心关键 IT 电力需求和供应。我们还将这一分析与Structure ResearchStructure Research整理的北美以外地区(亚太地区、中国、欧洲、中东和非洲、拉丁美洲)的区域总体估计相结合,以提供数据中心趋势的整体全球视图。我们通过跟踪各个集群来补充区域估计,并根据卫星图像和施工进度进行建设,例如位于新加坡以北几英里的马来西亚新山(主要由中国公司)的高达 1,000 兆瓦的开发管道。
这种跟踪是由超大规模企业完成的,很明显,从中期来看,人工智能领域的一些最大的参与者将在可部署的人工智能计算方面落后于其他参与者。
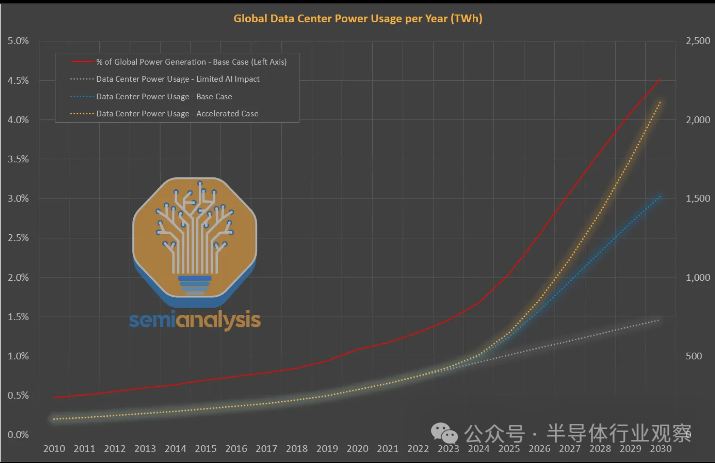
人工智能的繁荣确实会迅速加速数据中心能耗的增长,但短期内全球数据中心的用电量仍将远低于占总发电量24%的末日情景。我们相信,到 2030 年,人工智能将推动数据中心使用全球能源发电量的 4.5%。
真正的人工智能需求
未来几年,数据中心电力容量增长将从 12-15% 的复合年增长率加速至 25% 的复合年增长率。全球数据中心关键 IT 电力需求将从 2023 年的 49 吉瓦 (GW) 激增至 2026 年的 96 吉瓦,其中人工智能将消耗约 40 吉瓦。事实上,扩建并不是那么顺利,真正的电力紧缩即将到来。
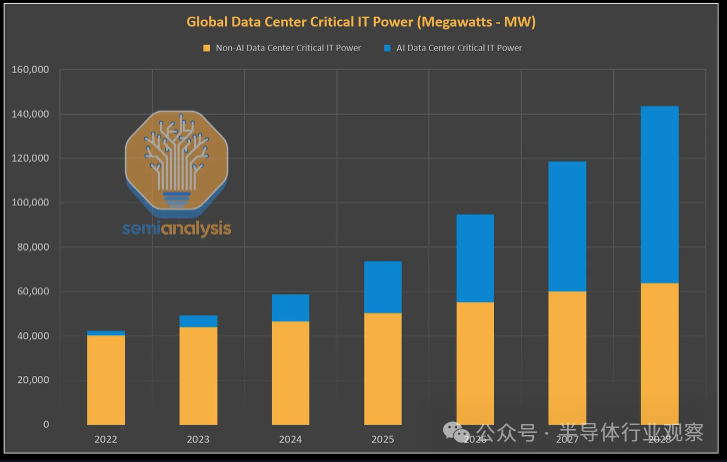
对丰富、廉价电力的需求,以及快速增加电网容量的同时仍满足超大规模企业的碳排放承诺,再加上芯片出口限制,将限制能够满足人工智能数据中心需求激增的地区和国家。
美国等一些国家和地区将能够以低电网碳强度、供应稳定的低成本燃料来源灵活应对,而欧洲等其他国家和地区将受到地缘政治现实和电力结构性监管限制的有效束缚。其他人只会简单地增加容量,而不关心环境影响。
训练和推理的关键需求
人工智能训练工作负载具有独特的要求,与现有数据中心部署的典型硬件的要求非常不同。
首先,模型训练数周或数月,网络连接要求相对限于训练数据进入。训练对延迟不敏感,并且不需要靠近任何主要人口中心。人工智能训练集群基本上可以部署在世界上任何具有经济意义的地方,但须遵守数据驻留和合规性法规。
要记住的第二个主要区别也有些明显——人工智能训练工作负载非常耗电,并且与传统的非加速超大规模或企业工作负载相比,运行人工智能硬件的功率水平往往更接近其热设计功耗 (TDP)。此外,虽然 CPU 和存储服务器的功耗约为 1kW,但每个 AI 服务器的功耗现在已超过 10kW。再加上对延迟的不敏感以及靠近人口中心的重要性降低,这意味着提供大量廉价电力(以及未来 - 访问任何电网供应)对于人工智能培训工作负载的相对重要性要高得多与传统工作负载相比。顺便说一句,其中一些是无用的加密货币挖矿作业所共有的要求,而单个站点没有超过 100 兆瓦的扩展优势。
另一方面,推理最终的工作量比训练更大,但它也可以相当分散。芯片不需要位于中心位置,但其庞大的体积将非常出色。
数据中心数学
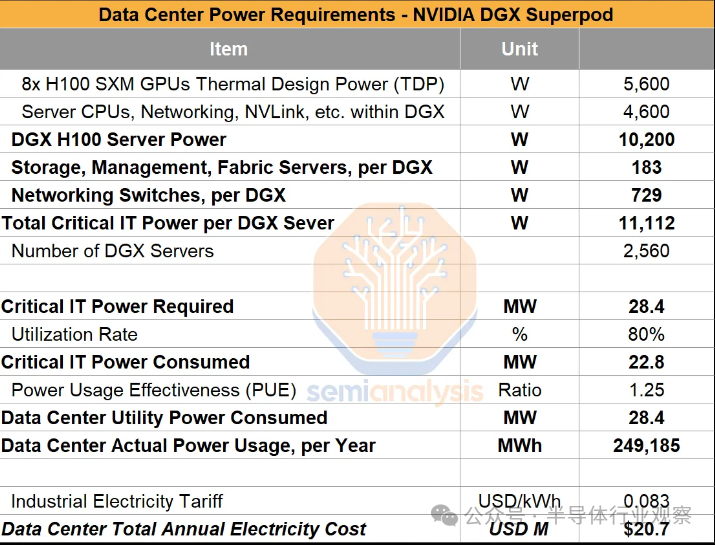
AI加速器具有较高的利用率(就功耗而言,而不是MFU)。每台 DGX H100 服务器正常运行时的预期平均功率 (EAP) 约为 10,200 W,每台服务器 8 个 GPU 的每一个 GPU 的功率为 1,275 W。其中包括 H100 本身的 700W 热设计功耗 (TDP),以及双 Intel Xeon Platinum 8480C 处理器的约 575W(分配给每个 GPU)以及 2TB DDR5 内存、NVSwitches、NVLink、NIC、重定时器、网络收发器等加上整个 SuperPOD 的存储和管理服务器以及各种网络交换机的电力需求,我们的有效电力需求为每台 DGX 服务器 11,112W 或每台 H100 GPU 1,389W。与我们考虑的 HGX H100 相比,DGX H100 配置在存储和其他项目方面有些过度配置。像 Meta 这样的公司已经发布了有关其完整配置的足够信息,以估计系统级功耗。

关键 IT 电源定义为数据中心楼层可用于服务器机架内的计算、服务器和网络设备的可用电力容量。它不包括数据中心运行冷却、电力输送和其他设施相关系统所需的电力。要计算本示例中需要构建或购买的关键 IT 电源容量,请将已部署 IT 设备的总预期电源负载相加。在下面的示例中,20,480 个 GPU(每个 GPU 功率为 1,389W)相当于所需的关键 IT 功率为 28.4 MW。
为了获得 IT 设备预计消耗的总功率(消耗的关键 IT 功率),我们需要应用相对于所需的关键 IT 功率的可能利用率。这一因素说明了 IT 设备通常不会以其设计能力 100% 运行,并且可能无法在 24 小时内得到相同程度的利用。在本例中,该比例设置为 80%。
除了关键 IT 电力消耗之外,运营商还必须提供冷却电力,以弥补配电损耗、照明和其他非 IT 设施设备。业界通过电力使用效率(PUE)来衡量数据中心的能源效率。计算方法是将进入数据中心的总电量除以运行数据中心内 IT 设备所用的电量。这当然是一个非常有缺陷的指标,因为服务器内的冷却被视为“IT 设备”。我们通过将消耗的关键 IT 功耗乘以电源使用效率 (PUE) 来解释这一点。PUE 较低表示数据中心能效更高,PUE 为 1.0 表示数据中心非常高效,没有冷却或任何非 IT 设备的功耗。典型的企业托管 PUE 约为 1.5-1.6,而大多数超大规模数据中心的 PUE 低于 1.4,一些专用构建设施(例如 Google 的)声称可以实现低于 1.10 的 PUE。大多数 AI 数据中心规格的目标是低于 1.3 PUE。过去 10 年,全行业平均 PUE 下降,从 2010 年的 2.20 下降到 2022 年估计的 1.55,这是节能的最大推动因素之一,并有助于避免数据中心功耗的失控增长。
例如,在利用率为 80% 且 PUE 为 1.25 的情况下,拥有 20,480 个 GPU 集群的理论数据中心平均将从电网获取 28-29MW 电力,每年总计 249,185 兆瓦时,这将花费 2070 万美元每年电力美元,基于美国每千瓦时 0.083 美元的平均电价。
数据中心布局和限制
虽然 DGX H100 服务器需要 10.2 千瓦 (kW) 的 IT 电源,但大多数托管数据中心仍然只能支持每个机架约 12 千瓦的电源容量,尽管典型的超大规模数据中心可以提供更高的电源容量。

因此,服务器部署将根据可用的电源和冷却能力而有所不同,在电源/冷却受限的地方仅部署 2-3 台 DGX H100 服务器,并且整排机架空间闲置,以将电力传输密度从 12 kW 翻倍至 24 kW。托管数据中心。实施此间隔也是为了解决冷却超额订购问题。
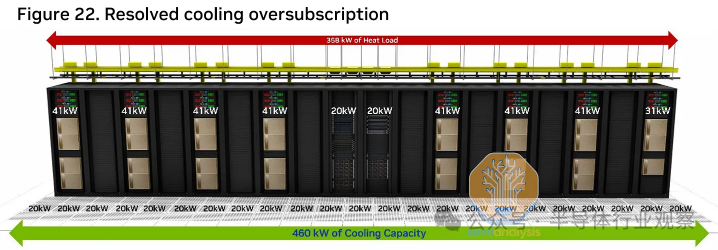
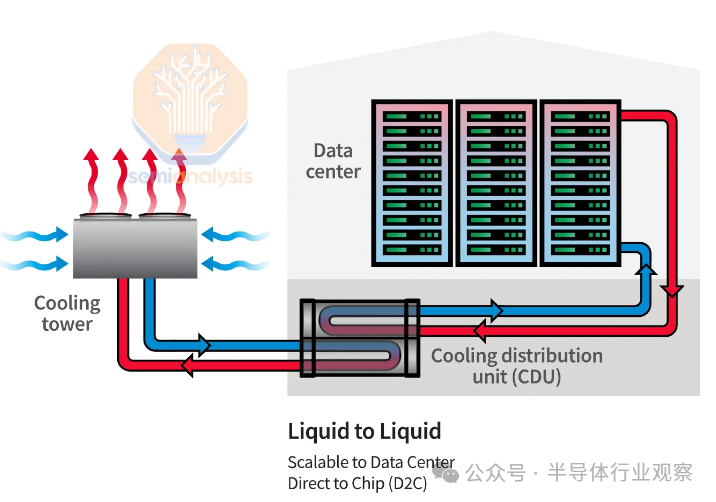
随着数据中心的设计越来越考虑人工智能工作负载,机架将能够通过使用专用设备增加气流来利用空气冷却来实现 30-40kW+ 的功率密度。未来使用直接芯片液体冷却为更高的功率密度打开了大门,通过消除风扇 功率的使用,可以将每个机架的功耗降低 10%,并通过减少或消除对环境的需求,将 PUE 降低 0.2-0.3空气冷却,虽然 PUE 已经在 1.25 左右,但这将是最后一波有意义的 PUE 增益。
许多运营商提出的另一个重要考虑因素是,各个 GPU 服务器节点最好彼此靠近,以实现可接受的成本和延迟。根据经验,同一集群中的机架距离网络核心最多应为 30 米。与昂贵的单模光收发器相比,短距离可实现更低成本的多模光收发器,单模光收发器通常可以达到数公里的距离。Nvidia 通常使用特定的多模光收发器将 GPU 连接到叶子交换机(leaf switches),其短距离可达 50m。使用更长的光缆和更长距离的收发器来容纳更远的 GPU 机架会增加成本,因为需要更昂贵的收发器。未来利用其他扩展网络技术的 GPU 集群也将需要非常短的电缆才能正常工作。例如,在Nvidia 尚未部署的 H100 集群的 NVLink 扩展网络中,该网络支持跨 32 个节点的多达 256 个 GPU 的集群,并且可以提供 57.6 TB/s 的全对全带宽,最大切换到开关电缆长度为 20 米。
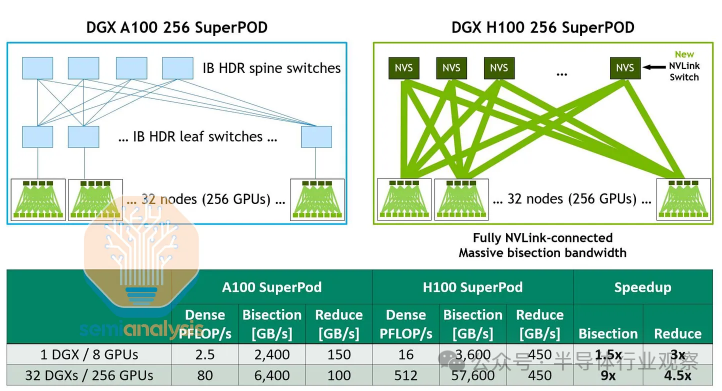
每个机架功率密度更高的趋势更多地是由网络、计算效率和每次计算成本考虑因素推动的——就数据中心规划而言,因为占地面积和数据大厅空间效率的成本通常是事后才考虑的。大约 90% 的托管数据中心成本来自电力,10% 来自物理空间。
安装IT设备的数据大厅通常只占数据中心总建筑面积的30-40%左右,因此设计一个大30%的数据大厅只需要整个数据中心的总建筑面积增加10%。考虑到80% 的 GPU 拥有成本来自资本成本80% ,其中, 20% 与托管相关(这会增加托管数据中心成本),因此额外空间的成本仅占 AI 总拥有成本的 2%-3%。
大多数现有托管数据中心尚未准备好支持每机架 20kW 以上的机架密度。芯片生产限制将在 2024 年显着改善,但某些超大规模和托管服务直接陷入数据中心容量瓶颈,因为它们在人工智能方面措手不及——尤其是在托管数据中心内,以及功率密度不匹配——其中 12-传统托管中的15kW功率将成为实现AI超级集群理想物理密度的障碍。
后门热交换器和直接芯片液体冷却解决方案可以部署在新建的数据中心中,以解决功率密度问题。然而,从头开始设计一个包含这些解决方案的新设施比改造现有设施要容易得多——意识到这一点,Meta 已停止开发计划中的数据中心项目,将其重新调整为专门针对人工智能工作负载的数据中心。
就所有超大规模数据中心的功率密度而言,Meta 的数据中心设计是最差的,但它们很快就醒悟并转变了。改造现有数据中心成本高昂、耗时,在某些情况下甚至可能不可能——可能没有物理空间来安装额外的 2-3 MW 发电机、不间断电源 (UPS)、开关设备或额外的变压器,并且重新设计管道以适应直接芯片液体冷却所需的冷却分配单元(CDU)并不理想。
人工智能需求与当前数据中心容量
使用基于我们的AI 加速器模型的加速器芯片的逐行单位出货量预测以及我们估计的芯片规格和建模的辅助设备功率需求,我们计算了未来几年的 AI 数据中心关键 IT 功率总需求。
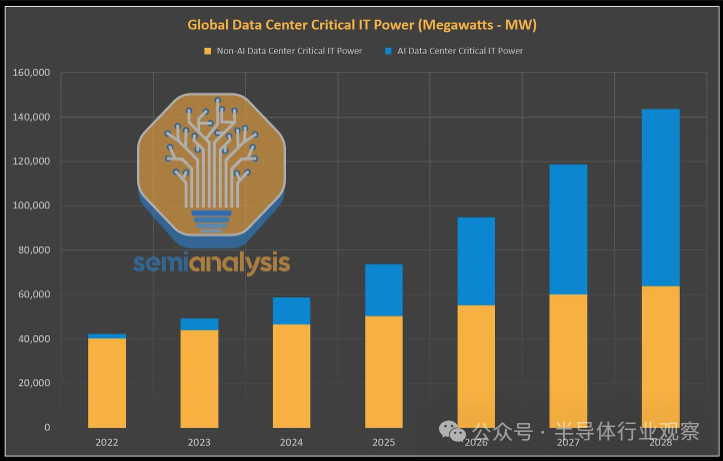
如上所述,数据中心关键 IT 电力总需求将从 2023 年的约 49 吉瓦翻倍至 2026 年的 96 吉瓦,其中 90% 的增长来自人工智能相关需求。这纯粹是出于芯片需求,但物理数据中心却讲述了不同的故事。
在美国,这种影响最为明显,我们的卫星数据显示,大多数人工智能集群正在部署和规划中,这意味着美国数据中心关键 IT 容量从 2023 年到 2027 年将需要增加两倍。
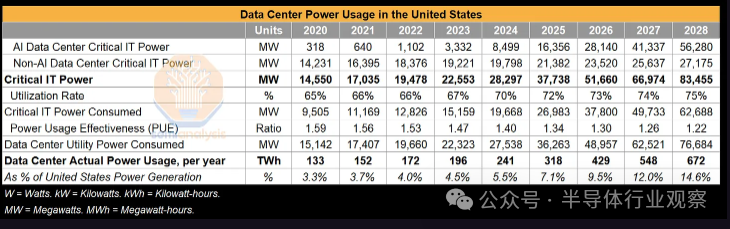
主要人工智能云推出加速器芯片的积极计划凸显了这一点。OpenAI计划在其最大的多站点训练集群中部署数十万个 GPU,这需要数百兆瓦的关键 IT 电源。通过查看物理基础设施、发电机和蒸发塔的建设,我们可以非常准确地跟踪它们的集群规模。Meta 预计到今年年底 H100 的安装量将达到 650,000 台。GPU 云提供商 CoreWeave 制定了在德克萨斯州普莱诺工厂投资 1.6B 美元的宏伟计划。这意味着计划斥资建设高达 50MW 的关键 IT 电源,并仅在该工厂安装 30,000-40,000 个 GPU,并为整个公司提供清晰的路径250MW 的数据中心占地面积(相当于 18 万个 H100),并且他们计划在单个站点中建设数百兆瓦的数据中心。
Microsoft 拥有人工智能时代之前最大的数据中心建设管道,他们也一直在吞噬一切可以利用的托管空间,并积极增加数据中心的扩建。像亚马逊这样的人工智能落后者已经发布了关于总装机容量为 1,000MW 的核动力数据中心的新闻稿,但需要明确的是,他们在实际的近期建设方面严重落后,因为他们是最后一个意识到人工智能的超大规模企业。谷歌和微软/OpenAI 都计划开发超过千兆瓦级的训练集群。
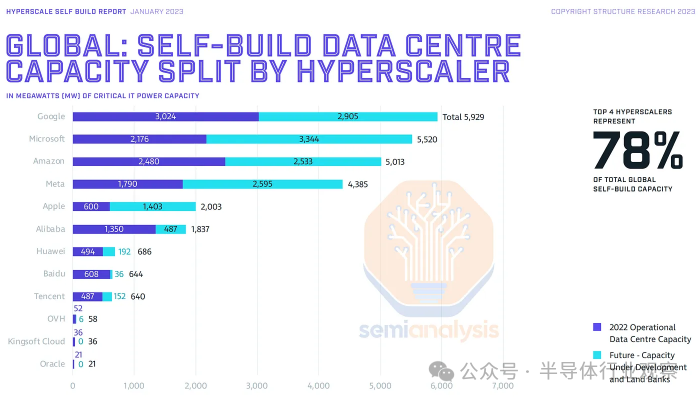
从供应角度来看,卖方一致估计 Nvidia 在 2024 年出货 300 万个以上 GPU 将对应超过 4,200 MW 的数据中心需求,接近当前全球数据中心容量的 10%,仅相当于一年的 GPU 出货量。当然,对英伟达出货量的普遍估计也是非常错误的。忽略这一点,人工智能只会在接下来的几年中增长,而 Nvidia 的 GPU 预计会变得更加耗电,路线图上有 1,000W、1,200W 和 1,500W GPU。Nvidia 并不是唯一一家生产加速器的公司,谷歌也在迅速提高定制加速器的产量。展望未来,Meta 和亚马逊还将加大其内部加速器的力度。
全球顶级超大规模企业并没有忽视这一现实——他们正在迅速加大数据中心建设和主机托管租赁力度。AWS 实际上以 6.5 亿美元购买了一个 1000MW核动力数据中心园区。尽管只有第一座容量为 48MW 的建筑可能会在短期内上线,但这为 AWS 提供了宝贵的数据中心容量管道,而无需等待发电或电网传输容量。我们认为,如此庞大的园区需要很多年才能完全达到承诺的 1,000 兆瓦关键 IT 电力。
人工智能训练和推理的碳和电力成本
了解训练流行模型的功率要求可以帮助衡量功率需求以及了解人工智能行业产生的碳排放。的碳足迹,175B 参数语言模型 检查了在法国 CNRS 旗下 IDRIS 的 Jean Zay 计算机集群上训练 BLOOM 模型的功耗。该论文提供了人工智能芯片 TDP 与集群总用电量(包括存储、网络和其他 IT 设备)之间关系的实证观察,一直到电网的实际用电量。
另一篇论文《Carbon Emissions and Large Neural Network Training》报告了其他一些模型的训练时间、配置和训练功耗。训练的功耗需求可能会有所不同,具体取决于模型和训练算法的效率(优化模型 FLOP 利用率 - MFU)以及整体网络和服务器电源效率和使用情况,但下面复制的结果是一个有用的衡量标准。
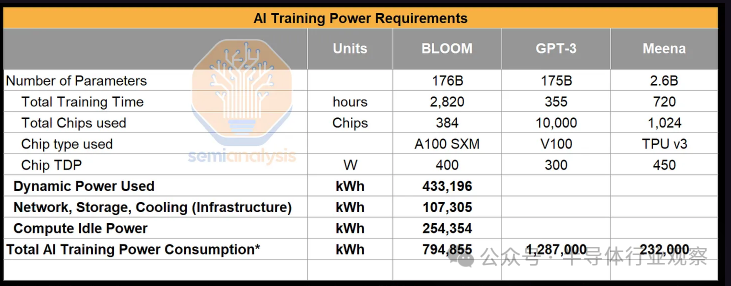
这些论文通过将总功耗(千瓦时)乘以数据中心运行的电网的碳强度来估计训练这些模型的碳排放量。目光敏锐的读者会注意到,法国训练 BLOOM 模型的碳强度非常低,为 0.057 千克二氧化碳当量/千瓦时,该国 60% 的电力来自核电,远低于美国 0.387 千克二氧化碳当量/千瓦时的平均水平。我们提供了一组额外的计算,假设训练作业在连接到亚利桑那州电网的数据中心上运行,亚利桑那州是目前数据中心扩建的领先州之一。
排放难题中要考虑的最后一个部分是体现排放,定义为制造和运输给定设备(在本例中为加速器芯片和相关 IT 设备)所涉及的总碳排放量。关于 AI 加速器芯片的具体排放量的可靠数据很少,但一些人粗略估计该数字为每个 A100 GPU 排放 150 千克二氧化碳当量,托管 8 个 GPU 的服务器排放 2,500 千克二氧化碳当量。经过计算,隐含排放量约为训练运行总排放量的 8-10%。
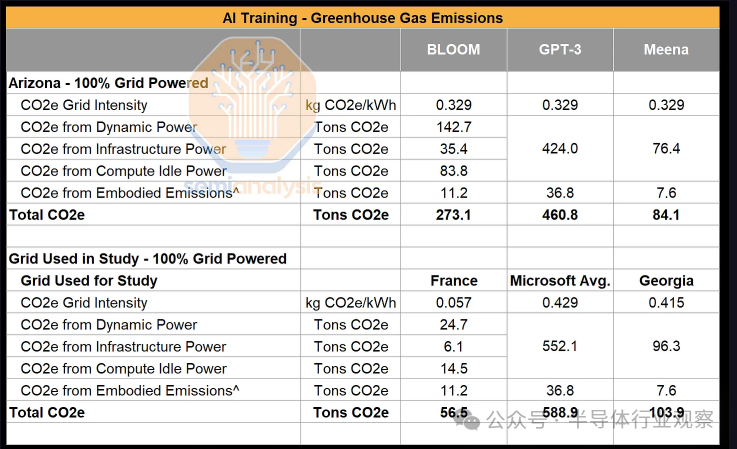
这些训练产生的碳排放量很大,一次 GPT-3 训练产生 588.9 吨二氧化碳当量,相当于128 辆乘用车的年排放量a。抱怨 GPT-3 训练排放就像回收塑料水瓶然后每隔几个月乘坐一次航班一样。字面上无关的美德信号。
另一方面,可以肯定的是,在确定最终模型之前,进行了多次训练迭代。2022 年, 在考虑可再生能源项目的任何抵消之前,Google 包括数据中心在内的设施总共排放了 8,045,800 吨二氧化碳当量。这意味着 GPT-3 并没有影响世界的碳排放,但是 GPT-4 的 FLOPS 增加了多个数量级,而当前的 OpenAI 训练运行比这个数量级高出一个数量级以上,训练的碳排放量为几年后将开始变得相当大。
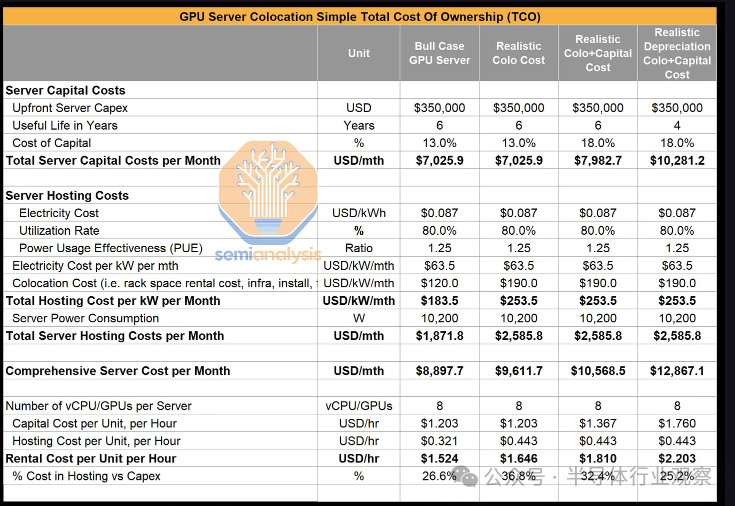
我们计算评估,配备 8 个 GPU 的典型 H100 服务器每月会排放约 2,450 千克二氧化碳当量,需要 10,200 瓦 IT 电源 — 假设每千瓦时 (KWh) 0.087 美元,每月成本为 648 美元。
来源:半导体行业观察


*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

