超越Intel 18A:18A-P、14A 和混合键合
抛开业务问题不谈,英特尔今天发布的公告的重点是该公司的晶圆厂路线图,该路线图将在两年多以来首次延期。现在,英特尔正在发货一些首批追赶节点,并准备发货其余节点,该公司将介绍 2025 年 18A 后的情况。

在高性能/高密度赛道上,这里的重要补充是 18A 的后继者14A。除其他成就外,14A 将是英特尔首次使用高数值孔径 (High-NA) EUV(下一代极紫外光刻技术)的节点。高数值孔径 EUV 有望实现更精细的特征,允许在不依赖多重图案化的情况下处理晶圆,而这对于较小节点尺寸的传统 EUV 来说是必需的。英特尔将其代工业务押注于 High-NA,这与英特尔在 EUV 领域的起步相对较晚(Intel 4/Meteor Lake 是其首款产品)形成鲜明对比,以至于英特尔已经获得了迄今为止全球唯一的高数值孔径扫描仪。
凭借 High-NA 的使用,14A 将成为英特尔继 20A/18A 合并之后的第一个完整节点。它将在功能尺寸和性能方面提供什么还有待观察——风险生产定于 2026 年底进行,这还需要几年时间——但如果一切按照英特尔的计划进行,这将是他们进一步发展的地方巩固其作为晶圆厂工艺技术领导者的地位。
在其他地方,英特尔正在计划其主要节点的几种变体,包括 14A。这些变体都获得了新的后缀,具体如下:
E,Feature Extension:E 节点是对以某种方式增强的节点的包罗万象的标签。据英特尔称,这主要基于新功能,例如支持更高的电压(想想用于 HPC 的台积电“X”节点)、更高的温度等。这些节点的性能也可能比基本节点更好,但一般来说,每瓦性能将提高不到 5%。
P, Performance Improvement:这些节点相对于节点的基本版本提供了更大但仍然适度的性能改进。AP 节点应提供 5% 到 10% 的每瓦性能改进。它们本质上是节点的“plus”版本。顺便说一句,如果一个新节点的每瓦性能提升超过 10%,那么英特尔表示我们应该期望它完全是一个新节点。
T, Through-Silicon Vias:最后,T 后缀将用于指示支持硅通孔 (TSV) 的英特尔节点的特殊版本,用于制造基础芯片,而基础芯片又用于铜铜混合键合。混合键合也是英特尔在其 Foveros Direct 3D 品牌下推广的,是当前芯片堆叠的最终游戏,允许使用微小的铜键合将芯片直接堆叠在彼此的顶部,这些铜键合使用 TSV 路由到各自的芯片中。混合键合/TSV 将允许凸块间距小于 10 微米,因此即使在一平方毫米内,芯片之间也能实现大量连接。
考虑到这些后缀,我们在英特尔路线图上看到了当前、即将推出和新宣布的工艺节点的几种变体。性能轨道上的是14A-E,它是英特尔最新路线图上最远的节点。英特尔没有透露此处提供的具体增强功能,但高压操作是一个不错的猜测。
同时,18A 将在 2025 年左右获得性能更高的变体,即18A-P。英特尔一再指出,18A 预计将是一个寿命较长的节点,因此看到它获得更高性能的变体也就不足为奇了,特别是因为其是一个不受高数值孔径光刻机设计限制的节点。(主要是芯片/掩模版尺寸)。
Intel 3 是英特尔首款大批量 EUV 节点,也将在未来几年内出现一些变化。这包括英特尔首个 TSV/Foveros Direct 节点、Intel 3-T以及将于 2025 年推出的功能增强型英特尔3-E 。最后,基于更高性能设计的第二个支持 TSV 的节点版本将随Intel 3P-T一起提供。值得注意的是,在英特尔路线图上,只有Intel 3 具有支持 TSV 的节点;由于这些 T 节点旨在用于工作软管基础模具,因此英特尔并未制定任何计划使用 18A 等尖端节点制造基础.芯片。(尽管毫无疑问,18A 仍将在 Foveros Direct 中用作top dies,例如在Clearwater Forest中)
最后,英特尔之前宣布的Intel 12 节点将于 2027 年投入生产。该预算节点正在与 UMC 联合开发,但将仅在英特尔代工厂生产。
英特尔:4年内5个节点已步入正轨
虽然英特尔今天发布的公告的重点是围绕他们未来的雄心壮志,但要实现这一目标,他们仍然需要实现当前的目标。这意味着他们承诺在 4 年内按时交付 5 个节点。

重要的是,英特尔再次重申 4 年计划仍在按计划进行。英特尔的 4 年计划结束时,18A 将于 2025 年投入生产,到 2024 年,客户已经可以开始为英特尔最雄心勃勃的节点设计芯片。
值得注意的是,英特尔最近完成了自己的 18A 主要产品Clearwater Forest 的流片,并于今天宣布。Clearwater 是基于英特尔第二代 E 核的 Xeon(Sierra Forest 的后继产品),是英特尔代工技术的杰作。除了用于计算元件的 18A 之外,Clearwater 还使用 Intel 3 作为其基础芯片,使用 EMIB 进行进一步的芯片连接,甚至使用 Foveros Direct(混合键合)进行芯片间连接。Clearwater 最终将与消费级Panther Lake一起成为英特尔的前两个大型 18A 项目。

凭借其特征尺寸、RibbonFET 晶体管和PowerVia 背面供电的组合,英特尔此前曾表示,他们希望通过 18A 重新获得工艺领先地位。截至今天的活动,这仍然是英特尔对何时重回巅峰的预测。
与此同时,距离生产更近了,英特尔报告称,其大批量 EUV 工艺节点Intel 3 已准备好进行大批量生产。它的前身 Intel 4 现已针对 Meteor Lake 发货,而 intel 3 是其改进版本,具有全系列可用的单元库(而不是仅提供高性能的 Intel 4)。
鉴于英特尔目前仅使用其 5 个节点中的第二个节点来交付产品,因此无法回避的事实是,至少作为外部观察者,英特尔的许多“步入正轨”声明都是在相信该公司的话。但鉴于英特尔的时间表从一开始就基于内部(风险生产)里程碑而不是产品出货里程碑,因此永远不会有任何其他方式。
尽管如此,尽管我们今天手里没有 Clearwater Forest 芯片,但他们的设计已经流片并已准备好接受客户设计这一事实,就像人们所希望的那样,是一个充满希望的迹象。
英特尔也很快宣称他们的客户胜利是他们进步的进一步证据,并且英特尔代工厂正走在正确的道路上。虽然英特尔没有透露任何具体合作伙伴的名称,但他们透露,他们已经就 18A 达成了 4 项“大型”交易。其中一项交易包括一项“有意义的”预付款协议。最终,英特尔代工厂的财务成功不仅取决于开发新节点,还取决于签约客户,以获得完成所有这些主要投资所需的必要数量。因此,对于英特尔来说,作为代工业务的相对新手,让客户愿意为产能预付费是他们的一大优势。
英特尔,未来依仗的技术
在今天一次采访中,英特尔通过分享其未来数据中心处理器的一瞥,概述了它将为其代工客户提供的新芯片技术。这些进步包括更密集的逻辑以及3D 堆叠芯片内的连接性增加 16 倍,它们将是该公司与其他公司的芯片架构师共享的首批高端技术之一。
在内部,英特尔计划在代号为 Clearwater Forest 的服务器 CPU 中使用这些技术的组合。该公司认为该产品是一种具有数千亿个晶体管的片上系统,是其代工业务的其他客户能够实现的目标的一个例子。
英特尔数据中心技术和探路总监Eric Fetzer表示,“我们的目标是让计算达到我们能够实现的最佳每瓦性能” 。这意味着使用该公司最先进的制造技术——Intel 18A。
“但是,如果我们将该技术应用于整个系统,就会遇到其他潜在问题,”他补充道。“系统的某些部分不一定能像其他部分一样扩展。逻辑通常可以根据摩尔定律很好地扩展一代又一代。”但其他功能则不然。例如,SRAM(CPU 的高速缓存)一直滞后于逻辑。连接处理器和计算机其余部分的 I/O 电路则更加落后。
面对这些现实,正如所有领先处理器制造商现在面临的那样,英特尔将 Clearwater Forest 的系统分解为其核心功能,选择最适合的技术来构建每个功能,并使用一套新技术将它们重新缝合在一起。其结果是 CPU 架构能够扩展到多达 3000 亿个晶体管。
在Clearwater Forest ,数十亿个晶体管被分为三种不同类型的硅 IC,称为芯片或小芯片,互连并封装在一起。该系统的核心是使用 Intel 18A 工艺构建的多达 12 个处理器核心小芯片。这些小芯片以 3D 方式堆叠在三个使用 Intel 3 构建的“基础芯片”之上,该工艺为今年推出的Sierra Forest CPU制造计算核心。CPU 的主高速缓存、电压调节器和内部网络将安装在基础芯片上。“堆叠通过缩短跳数来改善计算和内存之间的延迟,同时启用更大的缓存,”英特尔高级首席工程师Pushkar Ranade说。
最后,CPU 的 I/O 系统将位于使用 Intel 7 构建的两个芯片上,到 2025 年,该芯片将落后该公司最先进的工艺整整四代。事实上,这些小芯片与Sierra Forest 和 Granite Rapids CPU中的小芯片基本相同,从而减少了开发费用。
以下是所涉及的新技术及其提供的功能:
1
3D混合键合

英特尔当前的芯片堆叠互连技术 Foveros 将一个芯片与另一个芯片连接起来,采用的是长期以来芯片与封装连接方式的大幅缩小版:微小的焊料“微凸块”,短暂熔化后即可连接芯片。这使得 Meteor Lake CPU 中使用的 Foveros 版本大约每 36 微米建立一个连接。Clearwater Forest 将使用新技术Foveros Direct 3D,该技术不同于基于焊接的方法,可将 3D 连接的密度提高 16 倍。
它被称为“混合键合”,类似于将两个芯片表面的铜焊盘焊接在一起。这些垫片稍微凹陷并被绝缘体包围。当将两个芯片压在一起时,一个芯片上的绝缘体会粘附到另一芯片上。然后,对堆叠的芯片进行加热,使铜在间隙中膨胀并粘合在一起,形成永久链接。竞争对手台积电在某些AMD CPU中使用混合键合版本,将额外的高速缓存连接到处理器核心小芯片,并在AMD 最新的 GPU中将计算小芯片连接到系统的基础芯片。
Fetzer 表示,“混合键合互连能够大幅提高”连接密度。“这种密度对于服务器市场非常重要,特别是因为这种密度驱动着非常低的皮焦每比特通信。”如果每比特能源成本太高,则数据从一个硅芯片传输到另一个硅芯片所涉及的能量很容易消耗产品功率预算的很大一部分。Foveros Direct 3D 使每比特的成本降至 0.05 皮焦耳以下,这使其与在硅芯片内移动比特所需的能量处于同一水平。
节省的大部分能源来自于传输更少的铜线的数据。假设您想要将一个芯片上的 512 线总线连接到另一个芯片上相同大小的总线,以便两个芯片可以共享一组一致的信息。在每个芯片上,这些总线可能窄至每微米 10-20 根电线。要使用当今的 36 微米间距微凸块技术将信号从一个芯片传输到另一个芯片,意味着将这些信号分散到一侧数百平方微米的硅上,然后将它们聚集到另一侧的同一区域。Fetzer说,对所有额外的铜和焊料进行充电“很快就会成为延迟和大功率问题”。相比之下,混合键合可以在几个微凸块占据的同一区域中进行总线到总线的连接。
尽管这些好处可能很大,但转向混合键合并不容易。要形成混合键合,需要将已经切割的硅芯片与仍附着在晶圆上的硅芯片连接起来。正确对齐所有连接意味着芯片必须被切割成比微凸块技术所需的公差大得多的公差。修复和恢复也需要不同的技术。Fetzer 表示,甚至连接失败的主要方式也是不同的。对于微凸块,您更有可能因连接到相邻焊点的一点焊料而发生短路。但对于混合键合,危险是导致连接断开的缺陷。
2
背面电源
该公司今年通过其Intel 20A 工艺(将先于英特尔 18A 的工艺)为芯片制造带来的主要区别之一是背面供电。在当今的处理器中,所有互连,无论是承载电力还是数据,都构建在芯片的“正面”硅基板上方。Foveros 和其他 3D 芯片堆叠技术需要硅通孔、互连,这些互连可以向下钻穿硅以从另一侧建立连接。但背面电力传输更进一步。它将所有电源互连放置在硅下方,基本上将包含晶体管的层夹在两组互连之间。

这种布置会产生影响,因为电源互连和数据互连需要不同的功能。电源互连需要较宽以减少电阻,而数据互连应较窄以便可以密集封装。随着今年晚些时候Arrow Lake CPU的发布,英特尔将成为第一家在商用芯片中引入背面供电的芯片制造商。英特尔去年夏天发布的数据显示,仅背面电源就带来了6% 的性能提升。
英特尔 18A 工艺技术的背面供电网络技术将与英特尔 20A 芯片中的技术基本相同。然而,它在Clearwater Forest 中得到了更大的利用。即将推出的 CPU 在基础芯片中包含所谓的“片内电压调节器”。使电压调节接近其驱动的逻辑意味着逻辑可以运行得更快。距离越短,调节器就能更快地响应电流需求的变化,同时消耗更少的功率。
由于逻辑芯片使用背面供电,因此电压调节器和芯片逻辑之间的连接电阻要低得多。“通过技术提供的动力以及 Foveros 堆叠为我们提供了一种非常有效的连接方式,”Fetzer 说道。
3
RibbonFET,下一代晶体管
除了背面电源之外,该芯片制造商还采用英特尔 20A 工艺改用不同的晶体管架构:RibbonFET。自 2011 年以来, RibbonFET是纳米片或全栅晶体管的一种形式,它取代了FinFET(自 2011 年起 CMOS 的主力晶体管)。在 Intel 18A 中,Clearwater Forest 的逻辑芯片将采用第二代 RibbonFET 工艺制造。Fetzer 表示,虽然这些设备本身与 Intel 20A 中出现的设备没有太大区别,但设备的设计具有更大的灵活性。

他表示,“除了实现高性能 CPU 所需的功能之外,还有更广泛的设备可以支持各种代工应用”,而这正是 Intel 20A 工艺的设计目的。
其中一些变化源于 FinFET 时代失去的一定程度的灵活性。在 FinFET 出现之前,采用相同工艺的晶体管可以制成多种宽度,从而允许在性能(伴随更高电流)和效率(需要更好地控制漏电流)之间进行或多或少的连续权衡。由于 FinFET 的主要部分是具有规定高度和宽度的垂直硅鳍,因此现在必须采取设备具有多少鳍的形式进行权衡。因此,使用两个翅片可以使电流加倍,但没有办法将其增加 25% 或 50%。
有了纳米片器件,改变晶体管宽度的能力又回来了。“RibbonFET 技术可在同一技术基础上实现不同尺寸的焊带,”Fetzer 说道。“当我们从英特尔 20A 转向英特尔 18A 时,我们在晶体管尺寸方面提供了更大的灵活性。”
这种灵活性意味着设计人员可以用来构建系统的标准单元(基本逻辑块)可以包含具有不同属性的晶体管。这使得英特尔能够开发出一个“增强型库”,其中包括比英特尔 20A 工艺的标准单元更小、性能更好或更高效的标准单元。
4
第二代EMIB
在 Clearwater Forest 中,处理输入和输出的芯片使用第二代英特尔EMIB水平连接到基础芯片(具有高速缓存和网络的芯片) 。EMIB 是一小块硅,包含一组密集的互连和微凸块,旨在将一个芯片连接到同一平面上的另一个芯片。硅嵌入封装本身,以形成芯片之间的桥梁。

自 Sapphire Rapids 于 2023 年发布以来,该技术已在英特尔 CPU 中投入商业使用。它是一种成本较低的替代方案,可将所有芯片放在硅中介层上,硅中介层是一块带有互连图案的硅片,其大小足以容纳所有芯片。系统的芯片可供放置。除了材料成本之外,硅con 中介层的建造成本可能很高,因为它们通常比标准硅工艺设计的尺寸大几倍。
第二代 EMIB 今年与 Granite Rapids CPU 一起首次亮相,它将微凸块连接的间距从 55 微米缩小到 45 微米,并提高了电线的密度。这种连接的主要挑战是封装和硅在加热时以不同的速率膨胀。这种现象可能会导致翘曲,从而破坏连接。
此外,就 Clearwater Forest 而言,“还存在一些独特的挑战,因为我们将常规芯片上的 EMIB 连接到 Foveros Direct 3D 基础芯片和堆栈上的 EMIB”,Fetzer 说道。他说,这种情况最近被重新命名为 EMIB 3.5 技术(以前称为 co-EMIB),需要采取特殊步骤来确保所涉及的应力和应变与 Foveros 堆栈中的硅兼容,Foveros 堆栈比普通芯片更薄。
生态系统齐聚一堂:EDA 工具和 IP 已准备就绪
最后,今天活动的一部分专门面向英特尔以外的供应商,他们负责提供完成英特尔代工厂生态系统所需的其余工具、IP 和其他部分。
向合同制造的转变给英特尔带来了几项变化,其中最大的变化之一是如何为英特尔晶圆厂设计芯片。当英特尔只生产供内部使用的芯片时,该公司可以自由地使用他们需要的任何工具,无论他们需要什么工具——标准化的必要性并不高,更不用说向外界公开这些流程的工作原理了。但现在英特尔代工厂的大门已经敞开,英特尔必须与工具提供商密切合作,以便外部公司能够成功使用他们的晶圆厂。这意味着英特尔正在从完全内部生态系统过渡到外部生态系统;他们未来的成功部分取决于确保客户为其晶圆厂开发芯片的一切都到位。
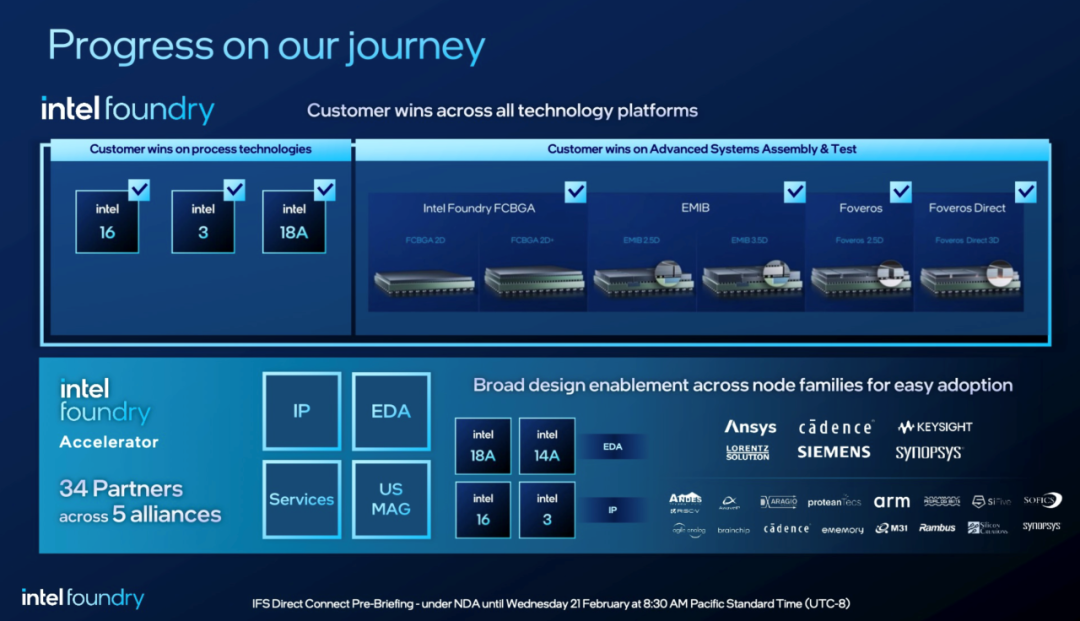
最终结果是,英特尔代工厂一直与电子设计自动化 (EDA) 提供商的知名企业合作,他们的工具是现代芯片设计的基础。这包括 Synopsys、Cadence、Ansys、西门子等。其中许多人将在今天早上的 Direct Connect 活动上发表讲话,宣布他们的工具已获得英特尔代工厂外部节点的认证。
有趣的是,Intel Foundry 今天还宣布围绕 EMIB 开展广泛的行业合作。我期待在今天上午晚些时候计划的 EDA 会议上听到更多相关信息,但据英特尔称,该公司一直在与 EDA 工具供应商合作,以简化 EMIB 在芯片设计中的使用,从而加快 EMIB 的开发和交付- 为英特尔代工客户配备的芯片。
除了 EDA 工具之外,英特尔还与 IP 提供商合作,以便将其关键 IP 移植到英特尔 Foundry 的工艺节点上或以其他方式开发。这是一个更大的合作伙伴列表,涵盖了从普通(内存 PHY)到 CPU 内核等复杂设计的所有内容。即使是最大的芯片设计商也不会完全在内部设计所有内容,因此获取充实芯片设计所需的基础 IP 块是英特尔代工生态系统的另一个主要需求。
总体而言,英特尔代工在过去几年中一直在吸引各种公司。但可以说,CPU 设计商 Arm 是英特尔最重要的 IP 供应商。除了基于 Arm 的芯片已经从英特尔曾经坚如磐石的数据中心业务中占据了很大份额(尤其是云供应商现在设计自己的芯片)之外,Arm 也是非常受欢迎的人工智能加速器组合 - 甚至 Arm 本身也是如此期待他们的下一代 Neoverse 设计。因此,如果英特尔代工厂想要进军新兴(且利润丰厚)的人工智能市场,他们不仅需要能够提供制造人工智能加速器的能力,还需要提供与之配套的CPU内核。
但在这方面,应该指出的是,英特尔本身也是这里的IP供应商。英特尔产品部门将作为小芯片/IP 供应商,甚至作为半定制设计公司来竞争业务,可以想象,该公司可以为真正需要定制级别的大客户提供基于英特尔 IP 的定制设计。出于显而易见的原因,今天公告的重点是围绕英特尔代工,但英特尔代工业务的成功将不仅仅是仅仅基于第三方 IP 为第三方制造芯片。
来源:半导体行业观察
--End--
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
