今年的 ISSCC 会议在旧金山举行,来自英特尔、AMD、台积电,甚至人工智能初创公司的多场演讲都在谈论他们过去的所作所为。然而,关于他们未来的工作的演讲总是吸引很多人参加。该展会还设有演示区,拥有硅片可供演示的公司将在此展示他们的硬件。除了 IBM 的 NorthPole(可能会得到自己的报道)、Axelera 的新型 AI 芯片、Rebellion 的 Atomus AI 芯片等之外,英特尔还展示了其最新的 3nm 硅内设计。
这不是 CPU 核心,而是 SERDES 连接。当芯片在封装上相互通信或与外界通信时,会建立一些连接,为了使该连接快速,数据从数字转换为模拟,然后串行化和反串行化。SER(序列化)和DES(反序列化)。PCIe 是使用 SERDES 连接的最常见接口,但 QPI 和网络等其他芯片到芯片协议也需要它们。在某些计算机中,它是现有最快的信号 IP,旨在传输片外数据。在新一代基于小芯片的系统中,芯片之间的连接将定义可以实现的带宽。因此,在过去 10 年中,我们看到了 SERDES 连接速度的增长——通道和绝对传输速度的增长。
例如,多年来使用 SERDES 的 PCIe 传输速率已从每秒 1 GB 提高到每秒 32 GB。然后,PCIe 利用多个 SERDES 链路(例如 x1、x2、x4、x8、x16)来倍增连接的整体带宽。PCIe作为一种协议引入了编码开销,因此SERDES链路的传输速率实际上高于PCIe的报价带宽,这对于SERDES链路类型来说是常见的。
到目前为止,我一直在假设 SERDES 链接只是发送 1 和 0,例如传统的二进制模式。在模拟世界中,这称为 NRZ,或不归零。这意味着信号可以是 1 或 0,在开发高速链路时,确保能够区分这两者至关重要。该领域的工程师和公司通常喜欢展示“眼图”,以表明其设计中 1 和 0 之间的差异。为了得到这个图,他们叠加了数千甚至数百万个连接周期,显示 1 或 0 不会互相干扰。
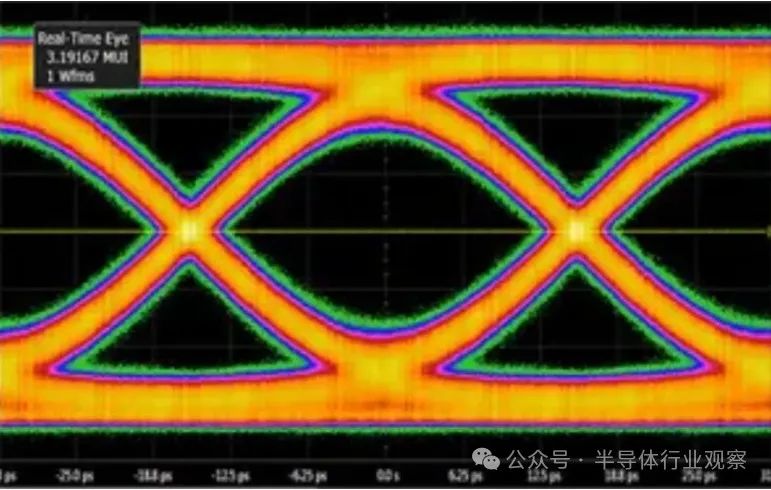
增加链路带宽(例如 8 GB 链路)的另一种方法是每次传输编码更多位。我们现在不再关注 NRZ,而是关注脉冲幅度调制 (PAM)。展示这一点的最简单方法是一个示例,其中信号中有四个级别,称为 PAM-4:
该信号现在传输四个值之一:11、10、01 或 00。因此,我们不能使用 PAM-4 提交两位信息,而不是使用 NRZ 传输一位信息。因此,PAM-4 处的 8 GT/s SERDES 链路的理论带宽为 16 Gbps。
对于更高速的连接,我报告了随着时间的推移,56 Gbps 和 112 Gbps 连接进入市场的情况。这些是多链路 SERDES 连接以及编码方案的变化的混合。这些技术不仅适用于网络或连接到 FPGA 的收发器,而且 GPU 到 GPU 连接也利用了这些高速连接。随着连接带宽的增加,公差和制造精度也大幅提高。因此,由于成本原因,我们经常看到这些高速连接首先在较旧的工艺节点(例如 28 纳米或 16 纳米)中展示,然后才进入可以提供更高效率的更密集的工艺节点。此外,根据应用的不同,如果可以应用更复杂的编码方案,则可以更容易地以较低的比特率开始传输。
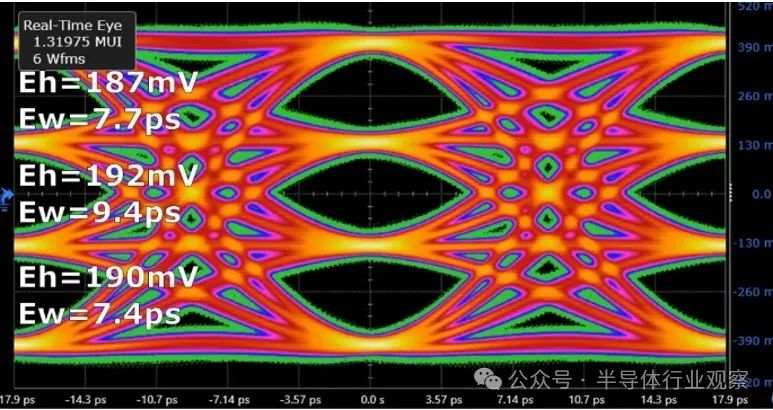
考虑到这一切,英特尔在 ISSCC 2024 上展示了一些令人印象深刻的芯片。它不仅适用于一些最快的 SERDES 连接带宽数字,而且还采用 3nm 硅——一种尚未商用的工艺节点。最重要的是,他们集成了 PAM-6 编码方案。该芯片名为 Bixby Creek。

PAM6 意味着每次传输编码更多位,但区分这些位也变得更加困难。与常规 NRZ 相比,如果 PAM4 提供 2 倍的带宽,那么 PAM6 总体上应提供 2.58 倍左右的带宽。不过,所有这些都具有相同的功率,因此在这种情况下它提供了令人难以置信的功率效率。

英特尔之前曾在 IEEE 活动中展示过 224 Gb/s,传输 (Tx) 为每比特 1.9 皮焦耳,接收 (Rx) 为每比特 1.4 皮焦耳(合计 3.3 pJ/位)。现在,当每秒传输 GB 字节时,该值可能很高 - 以 3.3 pJ/bit 的速度传输 1 Terabit 相当于 3.3 瓦。这一新演示将传输功率降低至每比特 0.92 pJ,将传输侧的功率减半,并在英特尔即将推出的工艺节点之一上实现。所有这些都在 0.15mm2 的硅中实现。

这在宏伟的计划中意味着什么?流程节点技术与任何流程节点非常相似,需要验证各种 IP 块,以便客户能够使用它们。对于任何构建新节点的代工厂来说,这意味着确保设计的数字逻辑和模拟部分协同工作。
对于英特尔来说,他们正在为其新节点实施一种滴答平台 - 在intel 4 上,只有高速逻辑和一些 SERDES 将得到验证,但对于intel 3 来说,将为客户提供大量 IP,这就是为什么 Intel 3 是作为代工厂的一部分提供的。与intel 20A 类似,它专注于高速逻辑和一些 SERDES,但 18A 将为客户准备好并经过验证的全套 IP。
即便如此,英特尔仍将在内部和外部(台积电、三星)的各种节点上创建IP以供使用。它是仅供内部使用还是作为可许可的知识产权提供,取决于产品的性质。本文和演示的主要作者之一确认,英特尔在台积电和英特尔上提供了大量高速 SERDES 连接。
来源:半导体行业观察
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


