
Tachyum 本周表示,其已完成 Prodigy FPGA 仿真系统的最终构建,这对任何设计来说都是一个重要的里程碑。此外,该公司表示,将把其通用 192 核 Prodigy 处理器的生产时间 从 2024 年推迟到 2025 年,但强调其仍预计明年将全面推出搭载其处理器的服务器。
Tachyum 创始人兼首席执行官 Radoslav Danilak 博士表示:“在明年 Prodigy 处理器流片和量产之前,我们能够在开发过程中达到这个阶段,这是非常令人欣慰的。”
这个最终硬件原型对于实现超过“10 千万亿次可靠性测试”至关重要,这是 Tachyum 在 Prodigy 芯片投产前希望达到的里程碑。这些设备将有助于确保芯片在全面投产前满足极高的可靠性要求。
基于 FPGA 的最终版本的主要更新包括支持超过 128 个内核,而去年已升级到 192 个内核。还进行了其他增强,以支持更大容量的 DIMM、改进调试过程、通过经过修改的 BMC-UEFI 硬件简化通信,并更换板对板连接器以获得更好的体验。
Danilak 补充道:“我们始终致力于提供世界上最小、最快、最环保的通用芯片。确保在发布第一天就实现这一目标一直是我们的首要任务,我们很高兴即将发布这一改变行业的产品。”
通用型 Prodigy 处理器有望在通用、图形和 AI / ML 工作负载方面同样表现出色,最初定于 2020 年推出,计划于 2019 年流片。然而,它的发布面临多次延迟,计划从 2021 年推迟到 2022 年,然后推迟到 2023 年,后来又推迟到 2024 年。今年早些时候,Tachyum 宣布将在 2024 年下半年开始量产 Prodigy 处理器,不过这个模糊的时间表可能会延长到 12 月。现在,该公司显然再次更新了计划,表明量产将从 2025 年开始,这意味着它很可能无法实现在 2025 年第一季度开始对采用 Prodigy 处理器的参考服务器进行抽样的目标。然而,从 Tachyum 最近的公告中仍不清楚该芯片是否有望在 2024 年流片。
Tachyum 声称,其处理器在云任务方面可实现最高 4.5 倍于顶级 x86 处理器的性能,在高性能计算方面可实现最高 3 倍于领先 GPU 的性能,在 AI 应用方面可实现最高 6 倍的性能。然而,尽管有这些雄心勃勃的宣称,但尚未公开展示任何原型来证实该处理器的架构既能发挥作用,又能实现这些结果。
Tachyum 在流片前打造最后一批 FPGA 原型
Tchyum 日前宣布其 Prodigy FPGA 仿真系统的最终版本,该版本将于明年芯片生产和全面上市之前发布。作为公告的一部分,该公司还将终止之前向商业和联邦客户提供的原型系统购买计划。
这些最新的硬件 FPGA 原型单元将确保 Tachyum 在流片之前和第一批 Prodigy 芯片上市之前达到超过 10 千万亿次循环的极高可靠性测试目标。Tachyum 的软件仿真系统及其访问方式正在扩展,在 Prodigy 上游之前移植的开源软件将更加可用。
此最终版本中包含的其他修改包括:
在 Tachyum 去年将核心数量增加到 192 之后,在电路板之间添加信号以支持增加到 128 个以上的核心数量
进行了一些小修复以支持大容量 DIMM
其他调试改进
修改 BMC-UEFI 硬件以简化通信
更换板对板连接器以改善体验
Tachyum 创始人兼首席执行官 Radoslav Danilak 博士表示:“在明年 Prodigy 处理器流片和量产之前,我们达到了开发历程的这一阶段,这令人非常欣慰。我们始终坚定不移地致力于提供世界上最小、最快、最环保的通用芯片。确保在发布的第一天就实现这一目标一直是我们的首要任务,我们很高兴能够推出这一改变行业的产品。”
作为一款通用处理器,Prodigy 为所有工作负载提供业界领先的性能,它支持数据中心服务器,能够通过单一同质架构在计算域(如 AI/ML、HPC 和云)之间无缝且动态地切换。通过消除对昂贵的专用 AI 硬件的需求并大幅提高服务器利用率,Prodigy 显著降低了资本支出和运营支出,同时实现了前所未有的数据中心性能、功率和经济性。Prodigy 集成了 192 个高性能定制设计的 64 位计算核心,可为云工作负载提供高达最高性能 x86 处理器 4.5 倍的性能,为 HPC 提供高达最高性能 GPU 3 倍的性能,为 AI 应用提供 6 倍的性能。
从零开始打造通用处理器
在过去几年的时间里,人们一直在谈论加速计算将成为新常态,以及数据中心通用处理器时代已经结束,这是有充分理由的。我们已经没有办法在单个设备上以高效且经济的方式完成应用程序所需的所有复杂处理。
2020年,我们进行了一次思想实验,探讨如何针对特定目的精简芯片,将它们编织在单个封装内或跨插槽和节点,共同设计以专门运行非常精确的工作流程,因为任何通用处理器(混合 CPU、GPU、TPU、NNP 和 FPGA 的元素)在除批量经济性之外的所有方面都不是最优的。我们认为,这种针对数据中心计算的极端共同设计是世界最终的发展方向,我们只是将芯片架构和互连结合在一起以实现这一目标。
处理器新贵 Tachyum 的联合创始人兼首席执行官 Radoslav Danilak对此完全不以为然。事实上,Tachyum 设计的 Prodigy “通用处理器”正朝着完全相反的方向发展。
Danilak 表示,解决现代处理器设计中的臃肿和布线问题可以实现一个独立、完整、集成的处理器,他认为这种处理器可以完成我们认为需要一系列快速整数 CPU 引擎、GPU 或 FPGA 浮点引擎和 NNP 矩阵数学引擎才能完成的工作,所有这些都通过跨越socket和盒子的高速互连连接在一起。(但不要称其为混合芯片,因为 Tachyum 会就此与你争论。)虽然我们仍然认为将计算组件以固定比例锁定在每两到三年更新一次的单个芯片中(迫使它们以相同的速度发展)与尝试打包不同风格和容量的 chiplet 计算单元集合一样危险,但我们也钦佩 Danilak 和联合创始人首席架构师 Rod Mullendore 和软件副总裁 Igor Shevlyakov 设计的优雅,以及他们为数据中心计算带来的雄心。
在 21 世纪的第二个十年推出一款新处理器需要一定的自尊心和大量的实践经验。这是一个艰难的市场,我们已经看到计算设备的激增,这令人欣喜。但并不是每个人都能成功,情况总是如此。幸运的是,有风险投资资金可供使用,人们愿意押注能够设计新东西的人。
Tachyum 总部位于加利福尼亚州圣克拉拉,在斯洛伐克布拉迪斯拉发设有开发实验室,其团队中有许多经验丰富的工程师和高管。早在互联网泡沫初期,Danilak 就设计了自己的超长指令字 (VLIW) 处理器,几年后,他为一家名为 Gizmo Technology 的公司(我们从未听说过他的芯片)创建了一款具有 64 位处理和内存的无序执行 X86 处理器,之后在东芝担任东芝 7901 芯片的首席架构师,该芯片是 PlayStation2 游戏机中使用的 MIPS R5900 Emotion Engine 处理器的一个变体,可能还用于各种东芝微控制器和电子产品。
Danilak 在 Nishan Systems 做了一年的项目,创建了一个单芯片网络处理单元 (NPU),该单元整合了 20 种不同芯片的功能,之后他担任 Nvidia 的高级架构师,设计 nForce 4 GPU 和“Fermi”第一代 Tesla GPU 加速器的功能。2007 年离开 Nvidia 之后,就在 GPU 加速浪潮即将兴起之际,Danilak 找到了闪存制造商 SandForce,并创建了其自主研发的闪存控制器;2010 年,SandForce 以 3.77 亿美元的价格卖给了 LSI Logic。之后,Danilak 与他人共同创立了全闪存阵列制造商 Skyera,西部数据于 2015 年夏天以未公开的价格收购了该公司。在寻找新想法的一年里,Danilak 于 2016 年 9 月与 Mullendore 和 Igor Shevlyakov 共同创立了 Tachyum。
需要一个团队来创建处理器、软件堆栈并将其推向潜在客户,而 Tachyum 团队在这方面经验丰富。在互联网泡沫期间和之后,Mullendore 是 Nishan Systems 的高级架构工程师,之后他为存储区域网络交换机制造商 McData 工作过,当时 McData 是 EMC 的一部分,后来被出售给 Brocade Communications,收购后他留了一段时间。Mullendore 随后担任 SandForce 的首席架构工程师,然后他跟随 Danilak 来到 Skyera,现在又来到 Tachyum。
Tachyum 的另一位联合创始人 Shevlyakov 于 1990 年代初开始担任软件工程师,然后在互联网泡沫初期在俄罗斯的多家初创公司专注于编译器,在 1999 年至 2001 年的巅峰时期,他是实时操作系统制造商 Wind River 的高级编译器工程师。随后,Shevlyakov 在 MicroUnity 工作了十几年,该公司开发了一种名为 BroadMX 的 RISC/SIMD 处理器,旨在用于网络处理工作,他将 GNU 开源工具链移植到该处理器上。他与 Danilak 和 Mullendore 一起加入了 Skyera,在那里他将 GNU 工具链移植到公司创建的专有芯片上,以控制闪存,并致力于全闪存阵列中的闪存转换层的研究。西部数据收购 Skyera 后,Shevlyakov 继续与他的联合创始人合作,负责 Tachyum 的软件堆栈。
业务开发副总裁 Ken Wagner 也是联合创始人,曾就职于多家硅片初创公司;系统工程副总裁 Kiran Malwankar 是横向扩展存储制造商 Pavilion Data Systems 的创始人;超级计算机制造商 Encore Computer 和 Kendall Square 的联合创始人、AMD 首席技术官 Fred Weber 是顾问;曼彻斯特大学计算机科学教授 Steve Furber 也是顾问,他在 1980 年代设计了我们所知的 Arm 的第一款 32 位 Acorn RISC Machines 处理器;分布式系统专家 Christos Kozyrakis 经常与 Google 合作,他也是斯坦福大学教授,也是顾问。
Prodigy 芯片的设计已经进行了好几年,该公司拥有一个内部 System C 模拟器,可用于内部开发和基准测试。FPGA 硬件模拟器将于秋季推出,供研究使用,因为他们计划在年底完成流片。(它已经推迟了好几次,但这对于一般芯片,尤其是第一代芯片来说,都是正常的。)与当今许多先进芯片一样,它采用台湾半导体制造公司的 7 纳米工艺蚀刻而成。这种先进的制造工艺使其能够将大量组件塞进 290 平方毫米的设备中。
有趣的是,该设计集中于将电路块连接在一起的电线,然后将 Tachyum 认为合适的组件比例组合在一起,以吸引超大规模计算企业、高性能计算中心以及机器学习和推理农场。Danilak 说,问题在于电线越来越慢了。以下是一些熟悉的图表:Danilak告诉The Next Platform。
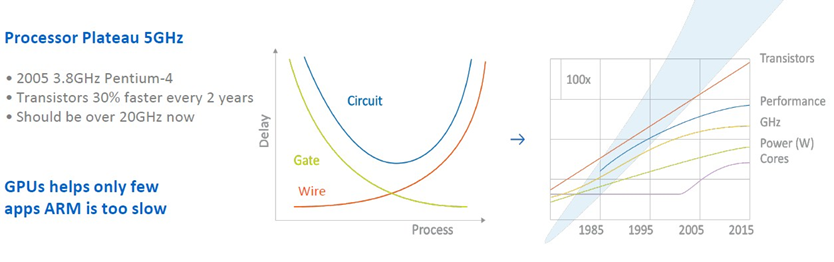
“我们的时钟速度性能稳定在稳定期,每个核心的性能并没有增加太多。核心数量在增加,但由于散热问题,我们也在降低时钟速度。所有晶体管都更快,但问题是电线越来越细,电阻越来越大,因此电线延迟也在增加。以前的芯片延迟是每毫米 100 皮秒,而现在则是每毫米 1,000 皮秒。”
当然,导线电阻会产生热量,但也会产生延迟,因此,根据 Danilak 的说法,诀窍是让导线尽可能短。这样,您可以比以前更快地为芯片提供时钟,同时还可以减少总计算时间(获取数据的时间加上处理数据的时间),从而完成更多工作。诀窍是从芯片上运行的工作负载中提取并行性,从而让导线延迟计算时间(就像缓存层次结构掩盖标准处理器中的计算延迟一样),这需要一些巧妙的编译器工作——因此,Shevlyakov 拥有如此丰富的编译器经验。
事不宜迟,以下是 Prodigy 芯片的裸片照片:

Danilak 大胆宣称:“每个核心都比 Xeon 核心或 Epyc 核心更快,并且比 Arm 核心更小,总体而言,我们的芯片在 HPC 和 AI 上比 GPU 更快。”
我们必须对该句中“快”的定义进行仔细研究,但显然,随着 Tachyum 将 Prodigy-1 芯片的时钟速度提高到 4 GHz,这比英特尔、AMD、Ampere Computing 和 Marvell 的顶级部件要快得多,并且与 IBM 在其 Power9 系列中生产的最快芯片相当。
Prodigy 芯片采用台积电的 7 纳米 FinFET 工艺的标准单元和 SRAM,该工艺具有 12 个金属层,工作电压为 0.825 伏。
处理器流水线的乱序执行由编译器处理,而不是硬件处理,因此关于这是一个有序处理器还是乱序处理器存在一些争议。Danilak 表示,Prodigy 芯片中的指令并行性是使用毒位提取的,这种技术在 Itanium 芯片中很流行,该核心在某些方面与 Itanium 芯片相似,并且还用于 Nvidia GPU。Prodigy 指令集为 32 个 64 位整数寄存器和 32 个矢量寄存器(宽度可以是 256 位或 512 位),外加 7 个矢量掩码寄存器。显式并行性(再次呼应 Itanium)由编译器提取,指令被捆绑成 3、8、12 或 16 字节的大小。管道每个周期可以执行两次加载、两次乘加、一次存储、一次地址递增、一次比较和一次分支 - 即每个周期八个 RISC-y 微操作,平均每个周期 1.72 条指令 -我们认为“Skylake”Xeon SP 核心可以做到这一点,而 Tachyum 实际上在其自己的图表中引用了我们的数据,这些数据来自多年来从英特尔拼凑起来的有关 IPC 的信息。
64 个内核分布在四个 16 核冗余块中,所有内核都通过其 L3 缓存通过网状互连连接;内存控制器通过与缓存不同的网状互连连接到内核,以避免网状拥塞。每个四核都有一对内存控制器,它们将支持 DDR4 或 DDR5 内存协议,以及在 SerDes 中实现的 18 条 PCI-Express 5.0 外围互连通道。在典型配置中,这些 SerDes 将用于实现每个四核的单个 PCI-Express 5.0 x16 以及一对 400 Gb/秒以太网控制器,但配置是灵活的。可以选择为这些芯片添加 HBM3 内存,这是针对 HPC 和 AI 工作负载的高端产品线的预期,这些工作负载的内存带宽需求高于 DDR4 甚至 DDR5 所能满足的内存带宽需求。但不要认为这会成为主流的 Prodigy 部件,也不要认为它会很便宜。
Danilak 表示,在 8 通道 DDR5 内存的情况下,当前的 HBM2 内存只能提供大约 2 倍的内存带宽,而且麻烦得多。“带宽处于可比范围内”,这正是 IBM 对Power9' 和 Power10 处理器配备的增强型 DDR4 和 DDR5 内存的评价。
现在,让我们深入了解 Prodigy 核心:
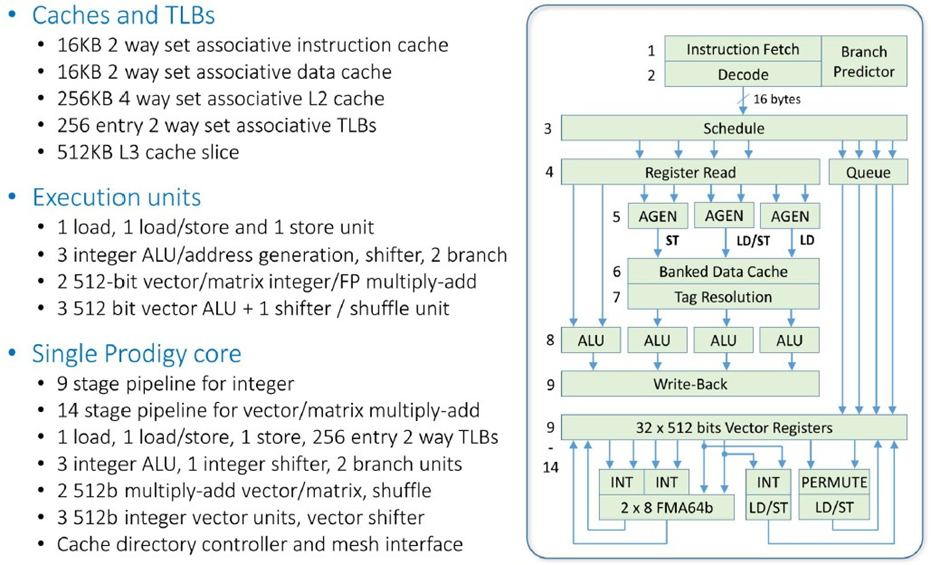
与其他核心设计相比,L1 缓存有点小,数据缓存为 16 KB,指令缓存为 16 KB,但核心上的 256 KB L2 缓存和核心上的 512 KB L3 缓存切片(它们交织在一起为整个芯片创建一个巨大的 32 MB 共享 L3 缓存)完全正常。如您所见,整数管道深度为九级,矢量管道又增加了五级。
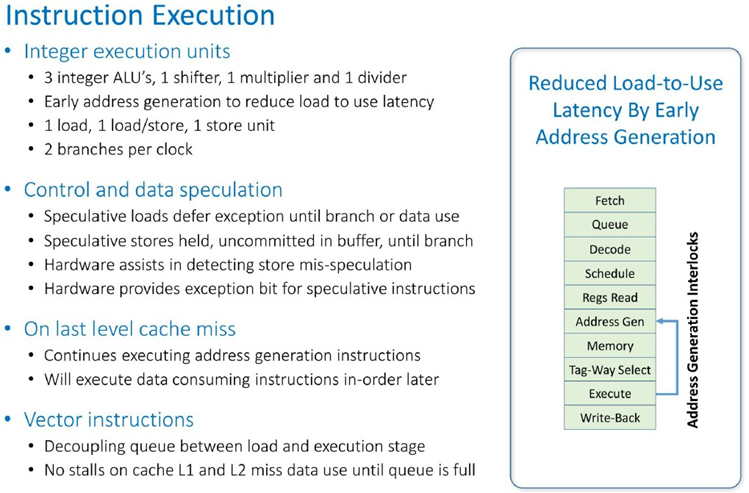
现在让我们为那些喜欢这些东西的人介绍一下详细情况。以下是 Prodigy 核心处理指令获取的方式:

指令执行的流程如下:
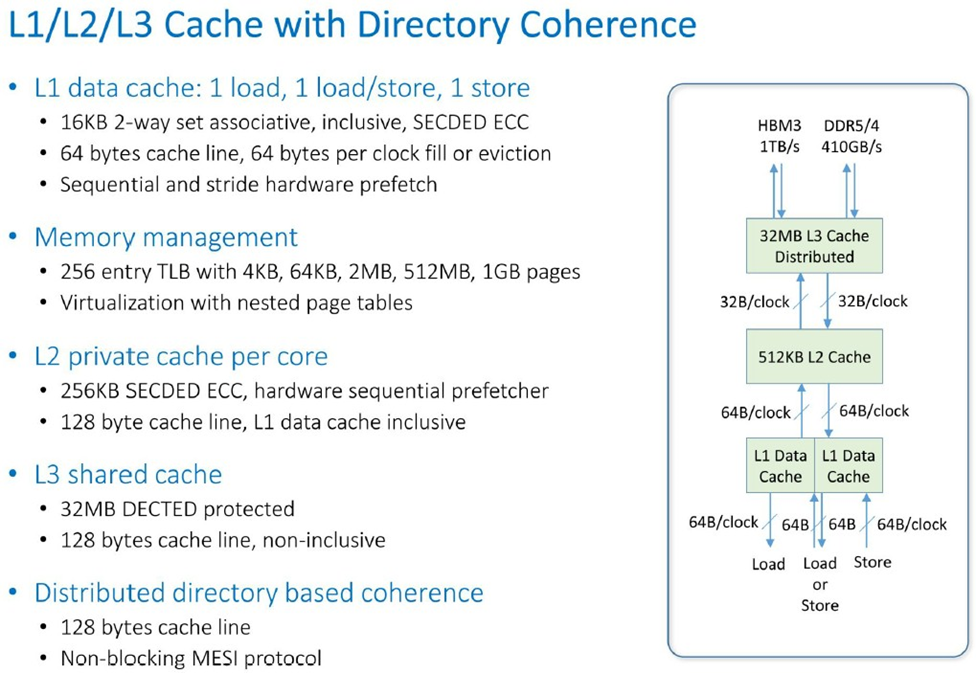
这是 Prodigy 芯片缓存层次的实际运行情况:
以下是向量和矩阵数学单元的布局和工作方式:
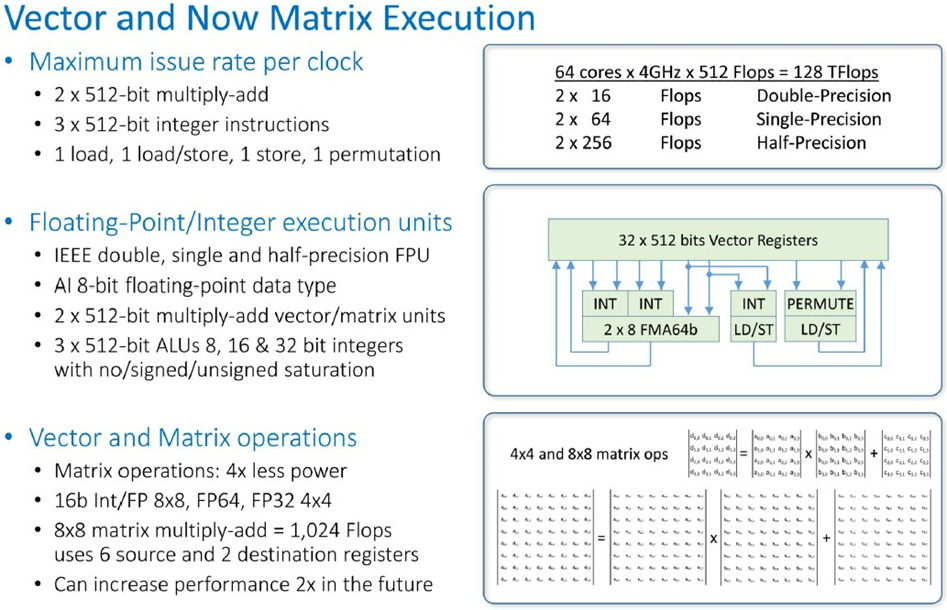
从这些图表中我们可以看出有几件事。
在从 L3 缓存到 DDR5 和 HBM3 内存的链路上,DDR5 内存的总带宽为 410 GB/秒,HBM3 内存的总带宽为 1 TB/秒。您确实需要 2 倍的带宽才能为 HBM3 支付额外费用 - 而且许多 AI 和 HPC 工作负载将从中受益,因为它们主要受限于内存带宽,而不是计算 - 这就是我们将这些应用程序分片并将它们放在如此多的服务器节点上的原因。
矢量单元将支持普通双精度 64 位 FP64 和单精度 32 位 FP32 运算,以及半精度 16 位 FP16 以及 16 位 bfloat16(由 Google 发明)和 8 位浮点(Tachyum 发明的专有格式)。矢量单元还支持 INT8、INT16 和 INT32 整数运算。这些矢量单元上还可以部署矩阵运算,允许对 FP32 和 FP64 数据进行 4×4 矩阵乘法运算,以及可以在 16 位或 8 位整数或浮点数据上运行的 8×8 矩阵乘法运算。矢量的这种双重任务确实非常有趣,Tachyum 暗示它可以在未来的处理器中将性能提高一倍。我们需要更深入地理解这一点,但看起来四个 512 位 SIMD 单元可以根据需要作为矢量或张量核心运行,这为这两种不同的数学运算方式释放了芯片空间。相比之下,Nvidia 的“Volta”和“Turing”GPU 具有不同种类和数量的整数、浮点和张量核心单元。
在 Danilak 看来,浮点乘加单元本质上是一样的——Nvidia 并不比其他公司更懂得如何做到这一点,他说。GPU 运行在 1.3 GHz 到 1.5 GHz 的频率下,而 CPU 乘加单元运行在 2.5 GHz 到 3 GHz 甚至有时 4 GHz 的频率下,它们提供的性能基本相同。
“CPU、GPU 和 TPU 的不同之处在于控制和计算能力的摊销。”简单来说,warp 有 32 个线程,运行速度大约是 Xeon 芯片中 AVX2 矢量单元的一半到三分之一,而后者可以执行四个“线程”浮点运算,功耗大约是后者的三分之一到四分之一。X86 芯片的分支预测非常昂贵,解码非常复杂。所有这些都增加了功耗,但性能比前几代 X86 芯片更好,但代价是不断降低时钟速度和增加线程。您可以迁移到 AVX-512 并获得两倍宽的矢量,但您必须移动得更慢。Prodigy 芯片的理念是拥有一种介于 CPU 和 GPU 之间的架构,去掉所有遗留的东西,尽可能缩短核心和其他元素之间的所有线路,以减少延迟,提高芯片上的时钟和网状结构速度,并提高整体性能,大概也是更划算的。
Prodigy“通用处理器”系列的初始 SKU 如下:

根据他们的最初计划,在 2020 年第一季度推出一款具有 128 个内核和四个 HBM 堆栈的双处理器机器,然后在 2020 年第二季度推出一款具有 64 个内核和八个 DDR4 内存控制器的单芯片,然后在 2020 年第三季度推出一款具有四个 DDR4 内存控制器的 32 核芯片。目前尚不清楚这是否仍然是推出的节奏,但时间显然已经推迟。
Tachyum 尚未确定价格,但有一些想法。Danilak 表示,标准 DDR4/DDR5 Prodigy SKU 的价格将在几百美元到几千美元之间,而配备 32 GB HBM3 内存的高端产品预计价格将低于 10,000 美元,性价比是 CPU 或 GPU 替代品的 3 倍(非常笼统地说)。
来源:半导体行业观察
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
